
Mysql之慢了怎么办?
一、慢查询日志(记录是谁慢了)
1、查询慢日志开关
mysql> show variables like '%slow_query_log%';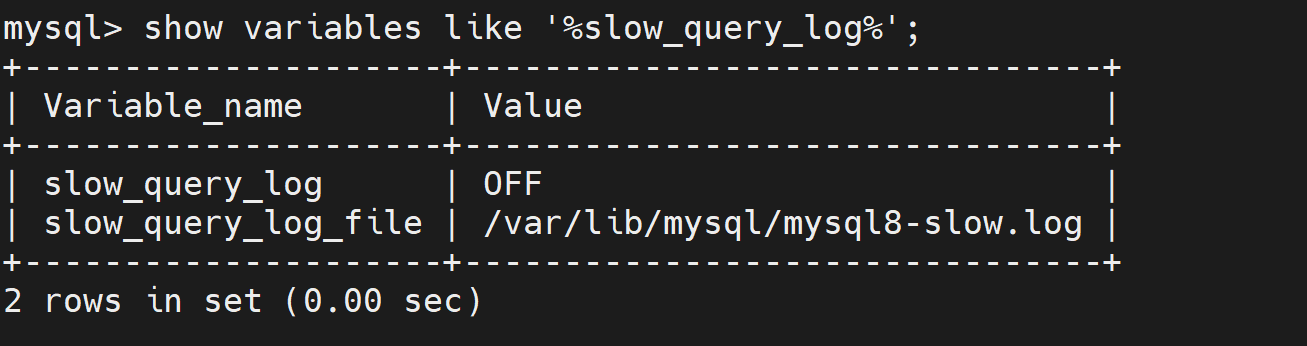
slow_query_log:慢日志状态关闭slow_query_log_file:慢日志文件位置/var/lib/mysql/mysql8-slow.log
2、开启slow_query_log
临时方式
#开启慢sql日志记录
mysql > set global slow_query_log='ON';
#关闭慢sql日志记录
mysql >SET GLOBAL slow_query_log=OFF;永久方式
在my.ini/my.cnf中修改
[mysqld]
slow_query_log=ON
#slow_query_log=OFF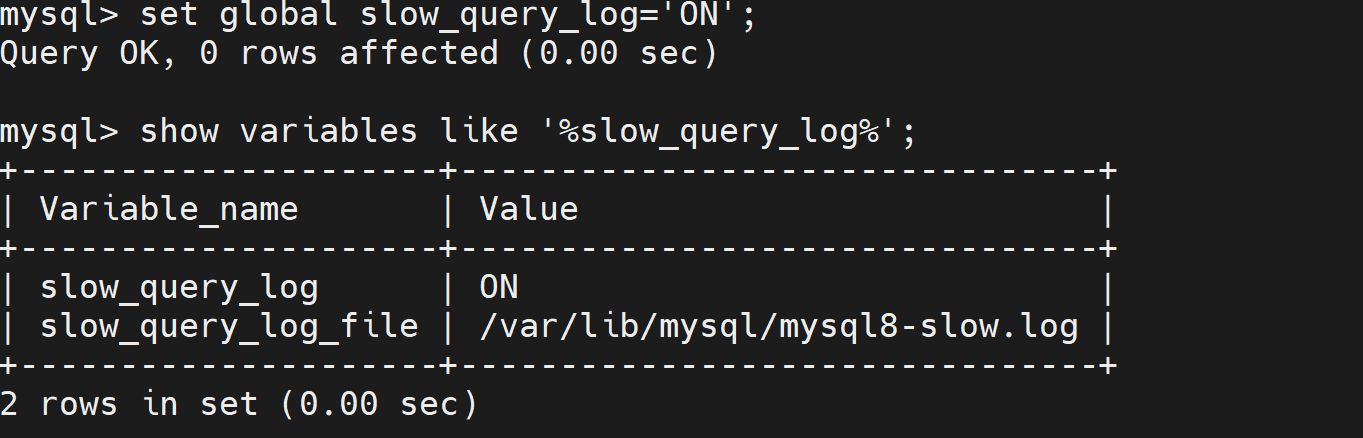 3、修改long_query_time阈值
3、修改long_query_time阈值
mysql > show variables like '%long_query_time%';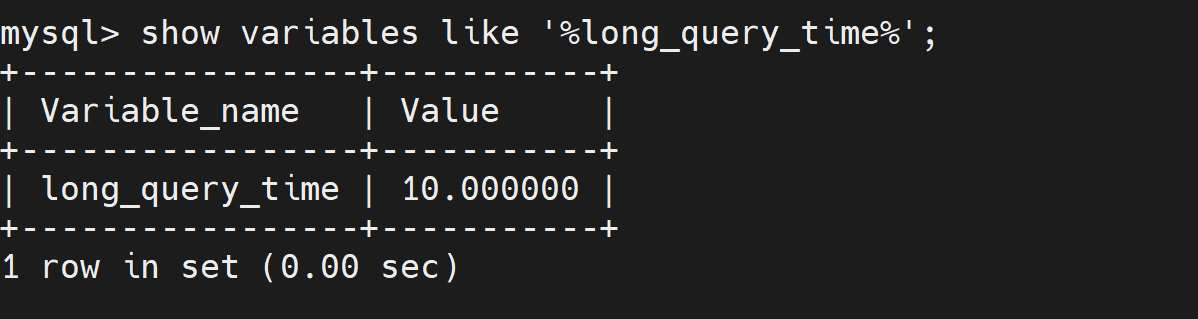 执行时间超过10s的sql才会记录到日志文件中
执行时间超过10s的sql才会记录到日志文件中
这里如果我们想把时间缩短,比如设置为 1 秒,可以这样设置:
#测试发现:设置global的方式对当前session的long_query_time失效。对新连接的客户端有效。所以可以一并
执行下述语句
mysql > set global long_query_time = 1;
mysql> show global variables like '%long_query_time%';
mysql> set long_query_time=1;
mysql> show variables like '%long_query_time%';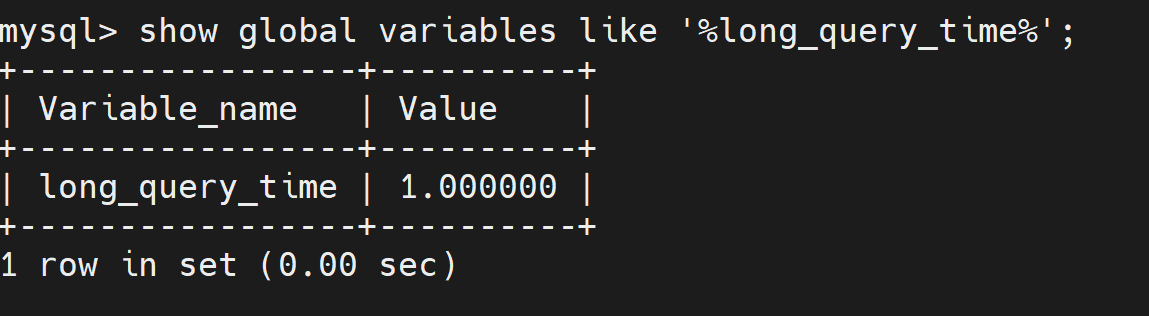 4、查看慢查询数目
4、查看慢查询数目
SHOW GLOBAL STATUS LIKE '%Slow_queries%'; 二、慢查询日志分析工具(找出慢SQL)
二、慢查询日志分析工具(找出慢SQL)
1、mysqldumpslow命令
-a: 不将数字抽象成N,字符串抽象成S
-s: 是表示按照何种方式排序:
c: 访问次数
l: 锁定时间
r: 返回记录
t: 查询时间
al:平均锁定时间
ar:平均返回记录数
at:平均查询时间 (默认方式)
ac:平均查询次数
-t: 即为返回前面多少条的数据;
-g: 后边搭配一个正则匹配模式,大小写不敏感的;
示例

常用参考
在命令行中执行,xxx为slow_query_log_file的位置,可通过上面的show variables like '%slow_query_log%';在mysql客户端中查询
#得到返回记录集最多的10个SQL
mysqldumpslow -s r -t 10 /var/lib/mysql/xxx-slow.log
#得到访问次数最多的10个SQL
mysqldumpslow -s c -t 10 /var/lib/mysql/xxx-slow.log
#得到按照时间排序的前10条里面含有左连接的查询语句
mysqldumpslow -s t -t 10 -g "left join" /var/lib/mysql/xxx-slow.log
#另外建议在使用这些命令时结合 | 和more 使用 ,否则有可能出现爆屏情况
mysqldumpslow -s r -t 10 /var/lib/mysql/xxx-slow.log | more2、SHOW PROFILE查看SQL执行成本
查看配置开关
mysql > show variables like 'profiling';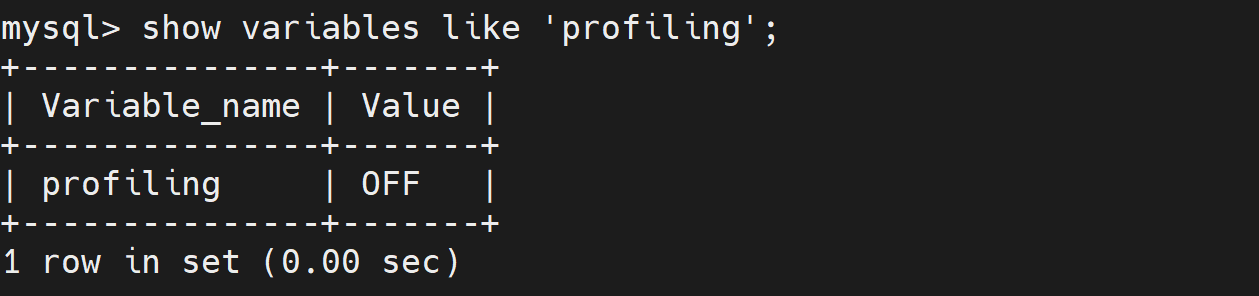 打开配置开关
打开配置开关
mysql > set profiling = 'ON';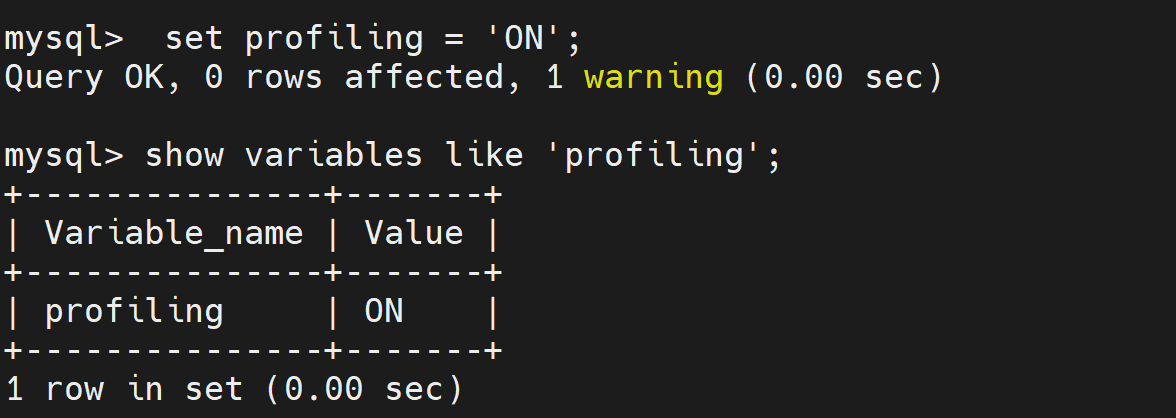 查询当前会话有哪些 profiles
查询当前会话有哪些 profiles
整体的sql执行情况
mysql > show profiles;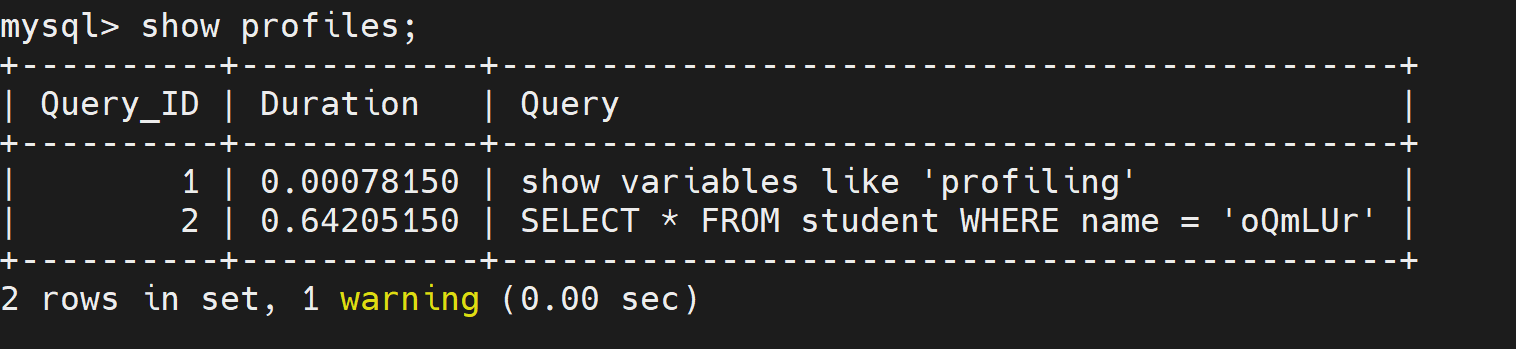 要查看查询的开销
要查看查询的开销
#查看最近一次的
mysql > show profile;
#查看制定Query_ID的
mysql > show profile for query 2;
#制定展示的其他参数
mysql> show profile cpu,block io for query 2;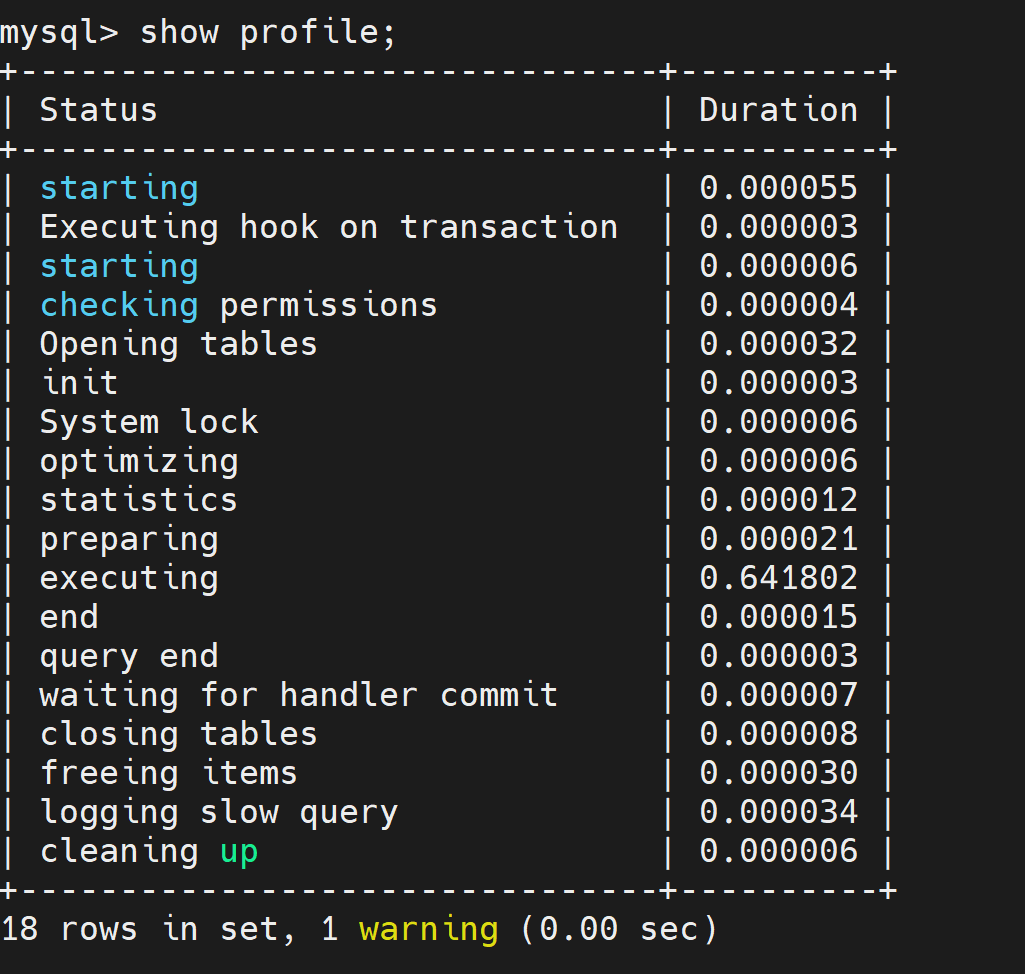 show profile的常用查询参数:
show profile的常用查询参数:
ALL:显示所有的开销信息。
BLOCK IO:显示块IO开销。
CONTEXT SWITCHES:上下文切换开销。
CPU:显示CPU开销信息。
IPC:显示发送和接收开销信息。
MEMORY:显示内存开销信息。
PAGE FAULTS:显示页面错误开销信息。
SOURCE:显示和Source_function,Source_file,Source_line相关的开销信息。
SWAPS:显示交换次数开销信息。
三、EXPLAIN分析查询语句(sql为啥慢了)
1、基本语法
mysql > EXPLAIN SELECT select_options
或者
mysql > DESCRIBE SELECT select_options2、基本组成

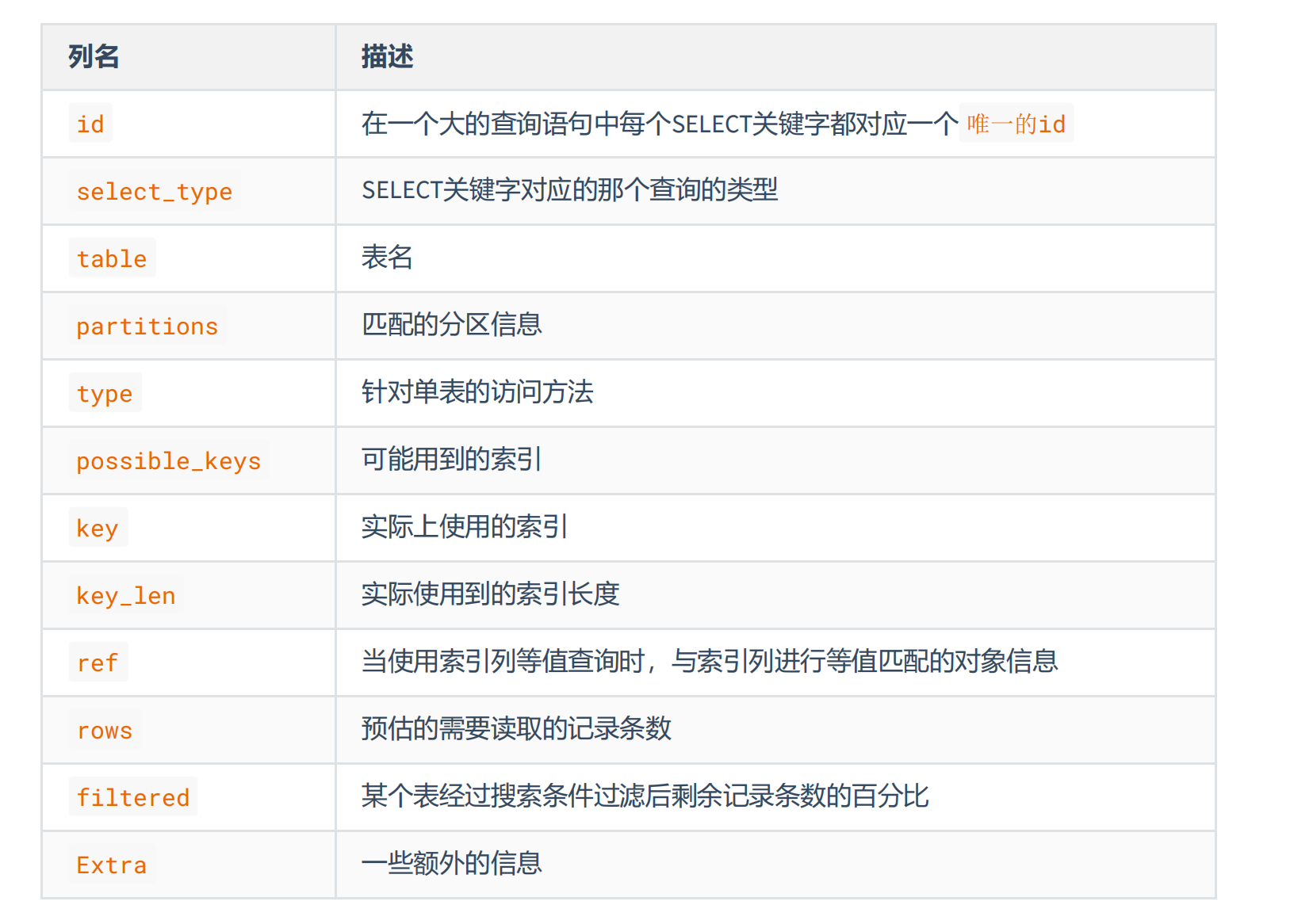 type字段特殊说明
type字段特殊说明
结果值从最好到最坏依次是: system > const > eq_ref > ref > fulltext > ref_or_null > index_merge >unique_subquery > index_subquery > range > index > ALL
SQL 性能优化的目标:至少要达到 range 级别,要求是 ref 级别,最好是 consts级别。(阿里巴巴开发手册要求)
ken_len特殊说明
代表的是具体使用索引字段的长度,在某些情况优化器会自动使用某些组合索引,但是可能使用组合索引的部分字段,就需要通过该字段计算出具体使用的索引列
int:4字节,为null的话5个字节,因为null也需要1个字节存储
varchar:指定的长度+是否为null(1个字节)+可变类型(2个字节),例如utf-8编码下,varchar(100)not null,则长度为100*3(utf-8字符集下一个字符三个字节)+0(不为null,不用存储)+2(记录可变类型)=102
3、EXPLAIN四种输出格式
EXPLAIN可以输出四种格式: 传统格式 , JSON格式 , TREE格式 以及 可视化输出 。
语法
# 传统格式
EXPLAIN SELECT ....
# JSON格式
EXPLAIN FORMAT=JSON SELECT ....
# TREE格式
EXPLAIN FORMAT=tree SELECT ....可以通过MySQL Workbench可视化查看MySQL的执行计划
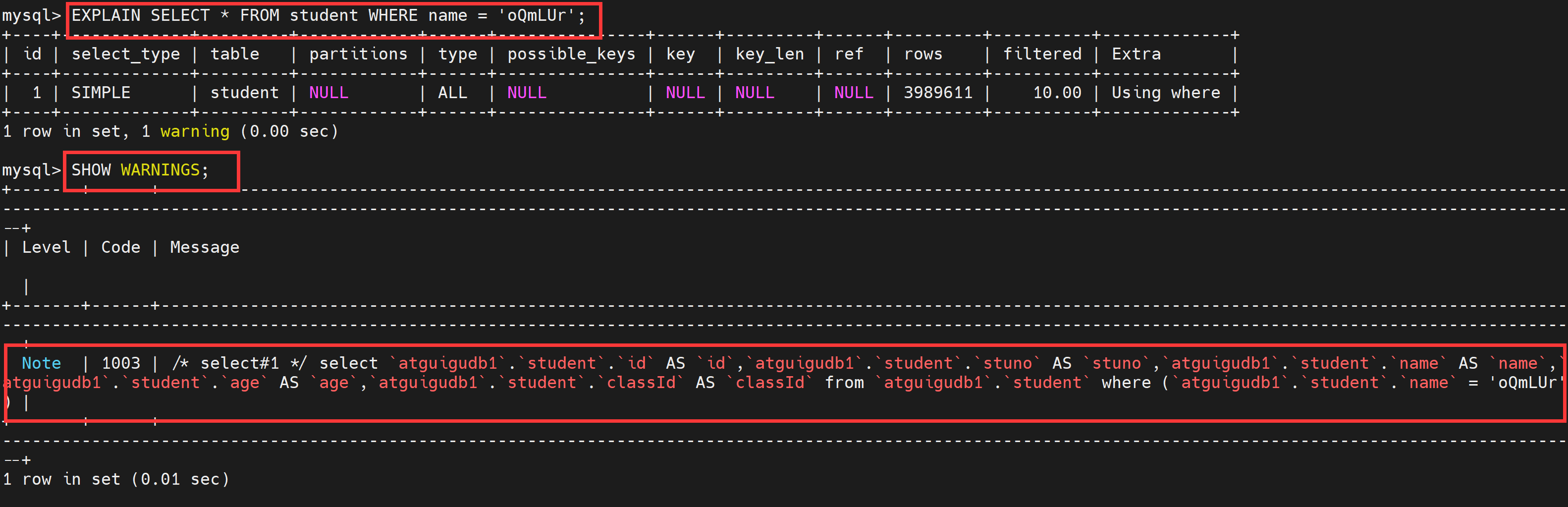
4、SHOW WARNINGS的使用
在explain之后使用使用show warninings可以查看优化器优化之后的sql结果
 四、trace分析优化器执行计划(整个sql的执行过程是怎么样的)
四、trace分析优化器执行计划(整个sql的执行过程是怎么样的)
1、开启trace分析优化器
#开启优化器堆栈记录,并且指定记录格式为json
SET optimizer_trace="enabled=on",end_markers_in_json=on;
#修改优化器堆栈内存,避免内存移除
set optimizer_trace_max_mem_size=1000000;2、测试
select * from student where id < 10;
select * from information_schema.optimizer_trace\G;五、MySQL监控分析视图
1、索引情况
#1. 查询冗余索引
select * from sys.schema_redundant_indexes;
#2. 查询未使用过的索引
select * from sys.schema_unused_indexes;
#3. 查询索引的使用情况
select index_name,rows_selected,rows_inserted,rows_updated,rows_deleted from sys.schema_index_statistics where table_schema='dbname' ;2、表相关
# 1. 查询表的访问量
select table_schema,table_name,sum(io_read_requests+io_write_requests) as io from sys.schema_table_statistics group by table_schema,table_name order by io desc;
# 2. 查询占用bufferpool较多的表
select object_schema,object_name,allocated,data from sys.innodb_buffer_stats_by_table order by allocated limit 10;
# 3. 查看表的全表扫描情况
select * from sys.statements_with_full_table_scans where db='dbname';3、语句相关
#1. 监控SQL执行的频率
select db,exec_count,query from sys.statement_analysis order by exec_count desc;
#2. 监控使用了排序的SQL
select db,exec_count,first_seen,last_seen,query from sys.statements_with_sorting limit 1;
#3. 监控使用了临时表或者磁盘临时表的SQL
select db,exec_count,tmp_tables,tmp_disk_tables,query from sys.statement_analysis where tmp_tables>0 or tmp_disk_tables >0 order by (tmp_tables+tmp_disk_tables) desc;4、IO相关
#1. 查看消耗磁盘IO的文件
select file,avg_read,avg_write,avg_read+avg_write as avg_io from sys.io_global_by_file_by_bytes order by avg_read limit 10;5、Innodb 相关
#1. 行锁阻塞情况
select * from sys.innodb_lock_waits;六、优化MySQL的参数
innodb_buffer_pool_size :这个参数是Mysql数据库最重要的参数之一,表示InnoDB类型的
表和索引的最大缓存。它不仅仅缓存 索引数据 ,还会缓存 表的数据 。这个值越大,查询的速度就会越快。但是这个值太大会影响操作系统的性能。key_buffer_size :表示
索引缓冲区的大小。索引缓冲区是所有的线程共享。增加索引缓冲区可以得到更好处理的索引(对所有读和多重写)。当然,这个值不是越大越好,它的大小取决于内存的大小。如果这个值太大,就会导致操作系统频繁换页,也会降低系统性能。对于内存在 4GB 左右的服务器该参数可设置为 256M 或 384M 。table_cache :表示
同时打开的表的个数。这个值越大,能够同时打开的表的个数越多。物理内存越大,设置就越大。默认为2402,调到512-1024最佳。这个值不是越大越好,因为同时打开的表太多会影响操作系统的性能。query_cache_size :表示
查询缓冲区的大小。可以通过在MySQL控制台观察,如果Qcache_lowmem_prunes的值非常大,则表明经常出现缓冲不够的情况,就要增加Query_cache_size的值;如果Qcache_hits的值非常大,则表明查询缓冲使用非常频繁,如果该值较小反而会影响效率,那么可以考虑不用查询缓存;Qcache_free_blocks,如果该值非常大,则表明缓冲区中碎片很多。MySQL8.0之后失效。该参数需要和query_cache_type配合使用。query_cache_type
当
query_cache_type=0时,所有的查询都不使用查询缓存区。但是query_cache_type=0并不会导致MySQL释放query_cache_size所配置的缓存区内存。当
query_cache_type=1时,所有的查询都将使用查询缓存区,除非在查询语句中指定SQL_NO_CACHE ,如SELECT SQL_NO_CACHE * FROM tbl_name。当
query_cache_type=2时,只有在查询语句中使用 SQL_CACHE 关键字,查询才会使用查询缓存区。使用查询缓存区可以提高查询的速度,这种方式只适用于修改操作少且经常执行相同的查询操作的情况。
sort_buffer_size :表示每个 需要进行排序的线程分配的缓冲区的大小 。增加这个参数的值可以提高 ORDER BY 或 GROUP BY 操作的速度。默认数值是2 097 144字节(约2MB)。对于内存在4GB左右的服务器推荐设置为6-8M,如果有100个连接,那么实际分配的总共排序缓冲区大小为100 × 6=600MB。
join_buffer_size = 8M :表示
联合查询操作所能使用的缓冲区大小,和sort_buffer_size一样,该参数对应的分配内存也是每个连接独享。read_buffer_size :表示
每个线程连续扫描时为扫描的每个表分配的缓冲区的大小(字节) 。当线程从表中连续读取记录时需要用到这个缓冲区。SET SESSION read_buffer_size=n可以临时设置该参数的值。默认为64K,可以设置为4M。innodb_flush_log_at_trx_commit :表示
何时将缓冲区的数据写入日志文件,并且将日志文件写入磁盘中。该参数对于innoDB引擎非常重要。该参数有3个值,分别为0、1和2。该参数的默认值为1。值为 0 时,表示 每秒1次 的频率将数据写入日志文件并将日志文件写入磁盘。每个事务的commit并不会触发前面的任何操作。该模式速度最快,但不太安全,mysqld进程的崩溃会导致上一秒钟所有事务数据的丢失。
值为 1 时,表示 每次提交事务时 将数据写入日志文件并将日志文件写入磁盘进行同步。该模式是最安全的,但也是最慢的一种方式。因为每次事务提交或事务外的指令都需要把日志写入(flush)硬盘。
值为 2 时,表示 每次提交事务时 将数据写入日志文件, 每隔1秒 将日志文件写入磁盘。该模式速度较快,也比0安全,只有在操作系统崩溃或者系统断电的情况下,上一秒钟所有事务数据才可能丢失。
innodb_log_buffer_size :这是
InnoDB 存储引擎的 事务日志所使用的缓冲区。为了提高性能,也是先将信息写入 Innodb Log Buffer 中,当满足 innodb_flush_log_trx_commit 参数所设置的相应条件(或者日志缓冲区写满)之后,才会将日志写到文件(或者同步到磁盘)中。max_connections :表示 允许连接到MySQL数据库的最大数量 ,默认值是 151 。如果状态变量connection_errors_max_connections 不为零,并且一直增长,则说明不断有连接请求因数据库连接数已达到允许最大值而失败,这是可以考虑增大max_connections 的值。在Linux 平台下,性能好的服务器,支持 500-1000 个连接不是难事,需要根据服务器性能进行评估设定。这个连接数 不是越大越好 ,因为这些连接会浪费内存的资源。过多的连接可能会导致MySQL服务器僵死
back_log :用于
控制MySQL监听TCP端口时设置的积压请求栈大小。如果MySql的连接数达到max_connections时,新来的请求将会被存在堆栈中,以等待某一连接释放资源,该堆栈的数量即back_log,如果等待连接的数量超过back_log,将不被授予连接资源,将会报错。5.6.6 版本之前默认值为 50 , 之后的版本默认为 50 + (max_connections / 5), 对于Linux系统推荐设置为小于512的整数,但最大不超过900。如果需要数据库在较短的时间内处理大量连接请求, 可以考虑适当增大back_log 的值。thread_cache_size : 线程池缓存线程数量的大小 ,当客户端断开连接后将当前线程缓存起来,当在接到新的连接请求时快速响应无需创建新的线程 。这尤其对那些使用短连接的应用程序来说可以极大的提高创建连接的效率。那么为了提高性能可以增大该参数的值。默认为60,可以设置为120。
wait_timeout :指定
一个请求的最大连接时间,对于4GB左右内存的服务器可以设置为5-10。interactive_timeout :表示服务器在关闭连接前等待行动的秒数。