
一、概念
ElasticSearch 是一个开源的 分布式、RESTful 搜索和分析引擎。使用 Java 语言开发,基于 Lucence开发。
Lucene是什么?
Lucene 是一个 Java 语言编写的高性能、全功能的文本搜索引擎库,提供强大的索引和搜索功能,以及拼写检查、高亮显示和高级分析功能。Lucene 并没有分布式以及高可用的解决方案,ElasticSearch 就是基于 Lucene 开发的,封装了许多 Lucene 底层功能,提供了简单易用的 RestFul API 接口和多种语言的客户端,开箱即用,自带分布式以及高可用的解决方案。
二、作用
可以用来解决使用数据库进行模糊搜索时存在的性能问题,适用于所有类型的数据,包括文本、数字、地理空间、结构化和非结构化数据。
例如:
实现各种网站的关键词检索功能,比如电商网站的商品检索,百度搜索
实现附近数据搜索
ELK的日志监控,Elasticsearch、Kibana、Beats 和 Logstash
......
三、基本概念
MySQL | Elasticsearch | 说明 |
Table(表) | Index | 索引(index),就是文档的集合,类似数据库的表(table) |
Row(行) | Document | 文档(Document),就是一条条的数据,类似数据库中的行(Row),文档都是JSON格式 |
Column(列) | Field | 字段(Field),就是JSON文档中的字段,类似数据库中的列(Column) |
Schema(表结构) | Mapping | Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema) |
SQL(查询语言) | DSL | DSL是elasticsearch提供的JSON风格的请求语句,用来操作elasticsearch,实现CRUD |
四、基本原理
ES底层采用倒排索引来加快查询效率。
1、倒排索引创建过程
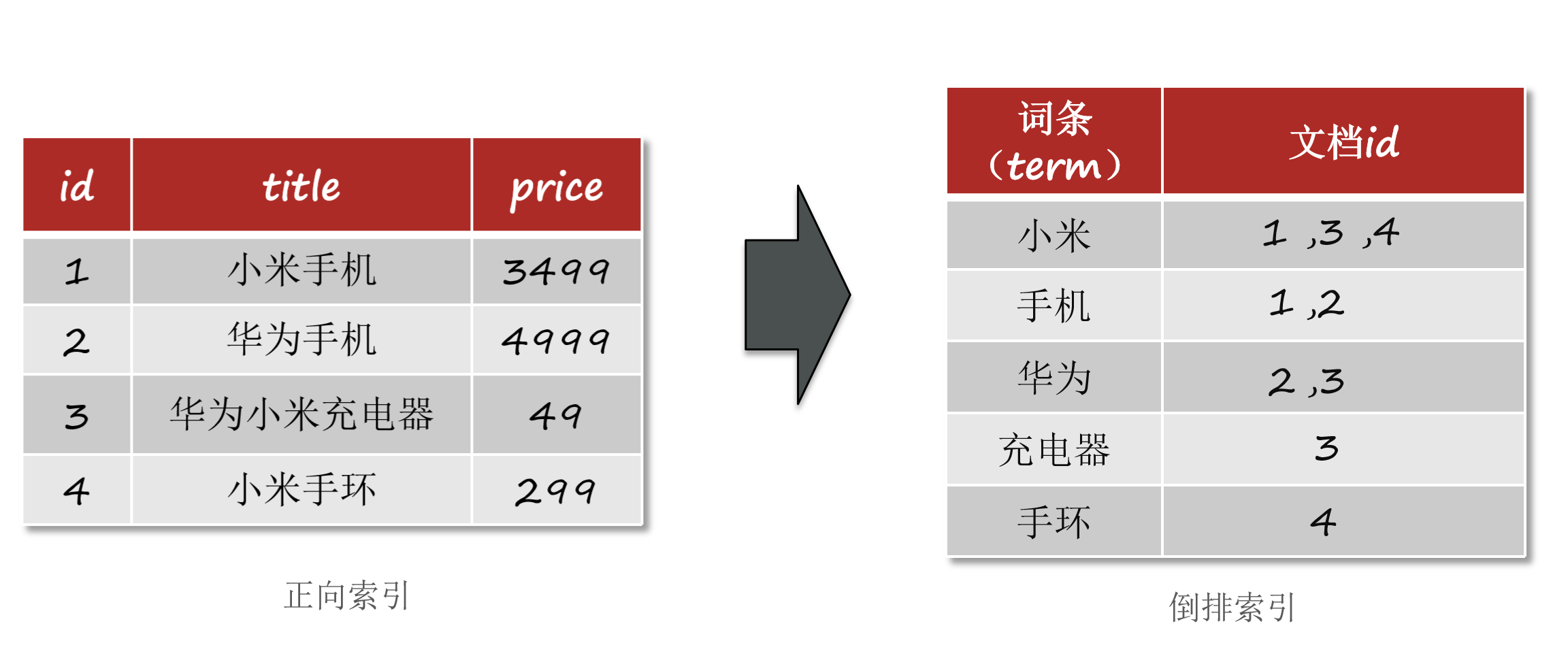
建立文档列表,每个文档都有一个唯一的文档 ID 与之对应。
通过分词器对文档进行分词,生成类似于 <词语,文档ID> 的一组组数据。
将词语作为索引关键字,记录下词语和文档的对应关系,也就是哪些文档中包含了该词语。
2、检索流程
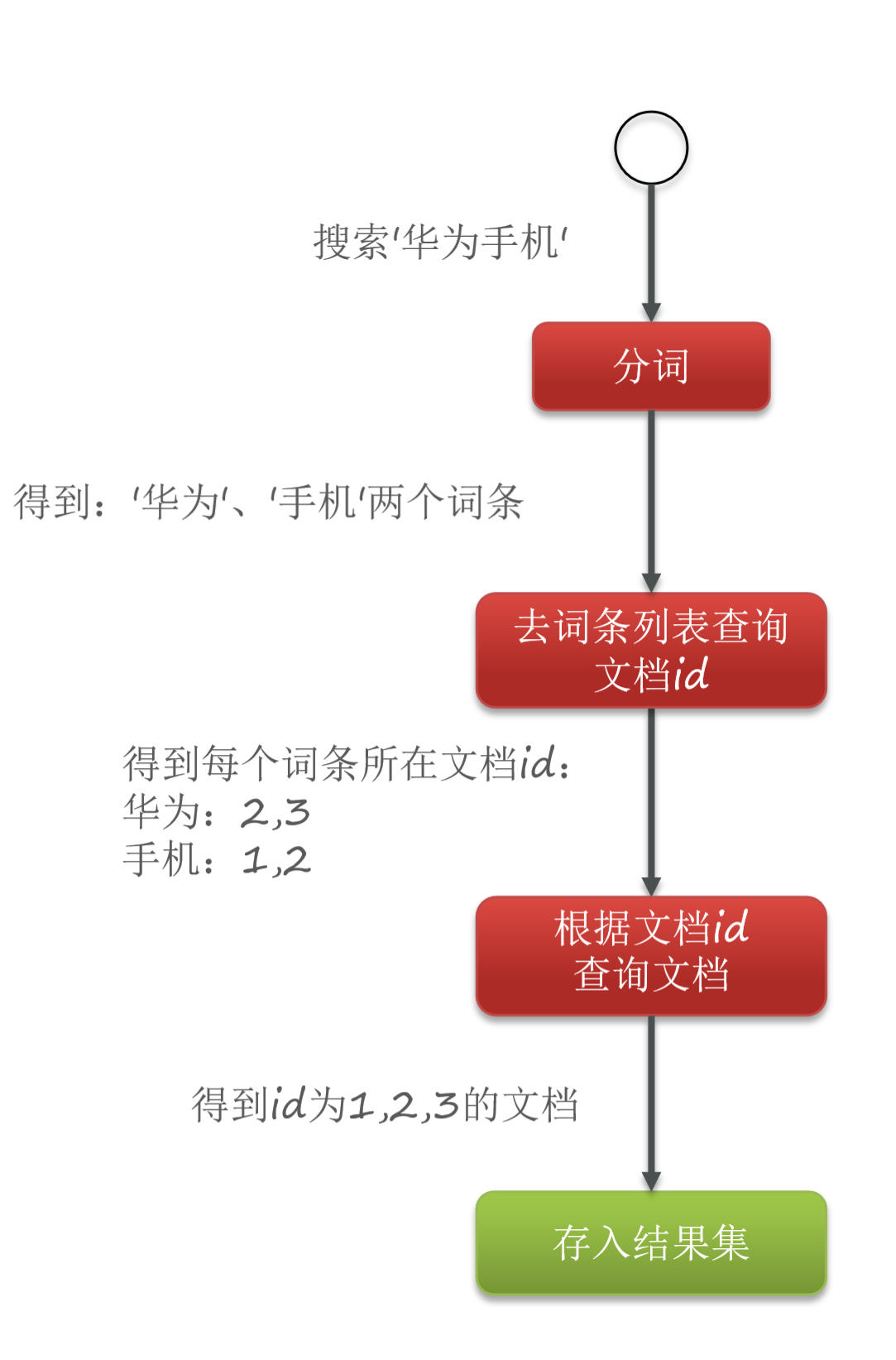
根据分词查找对应文档 ID
根据文档 ID 找到文档